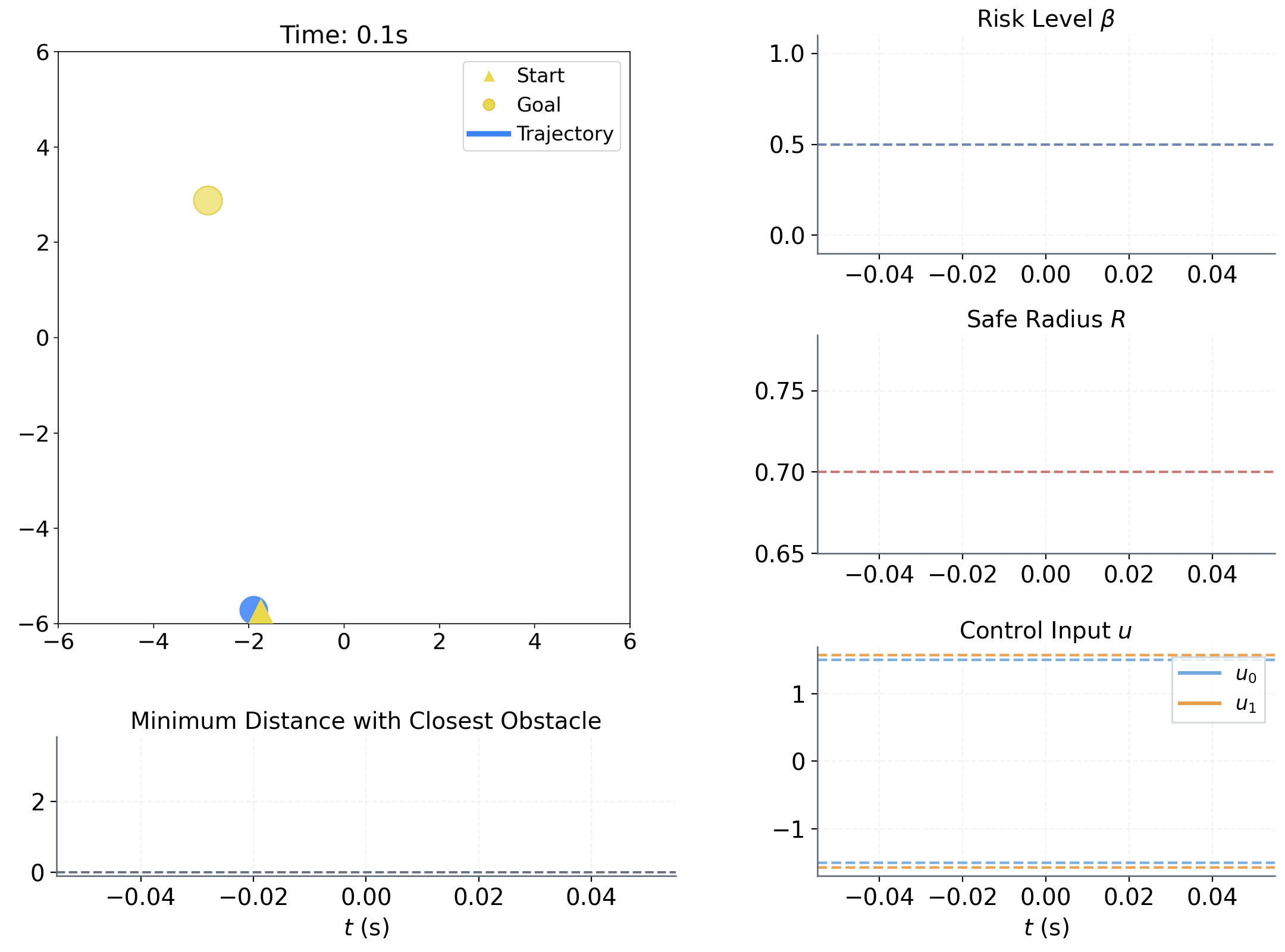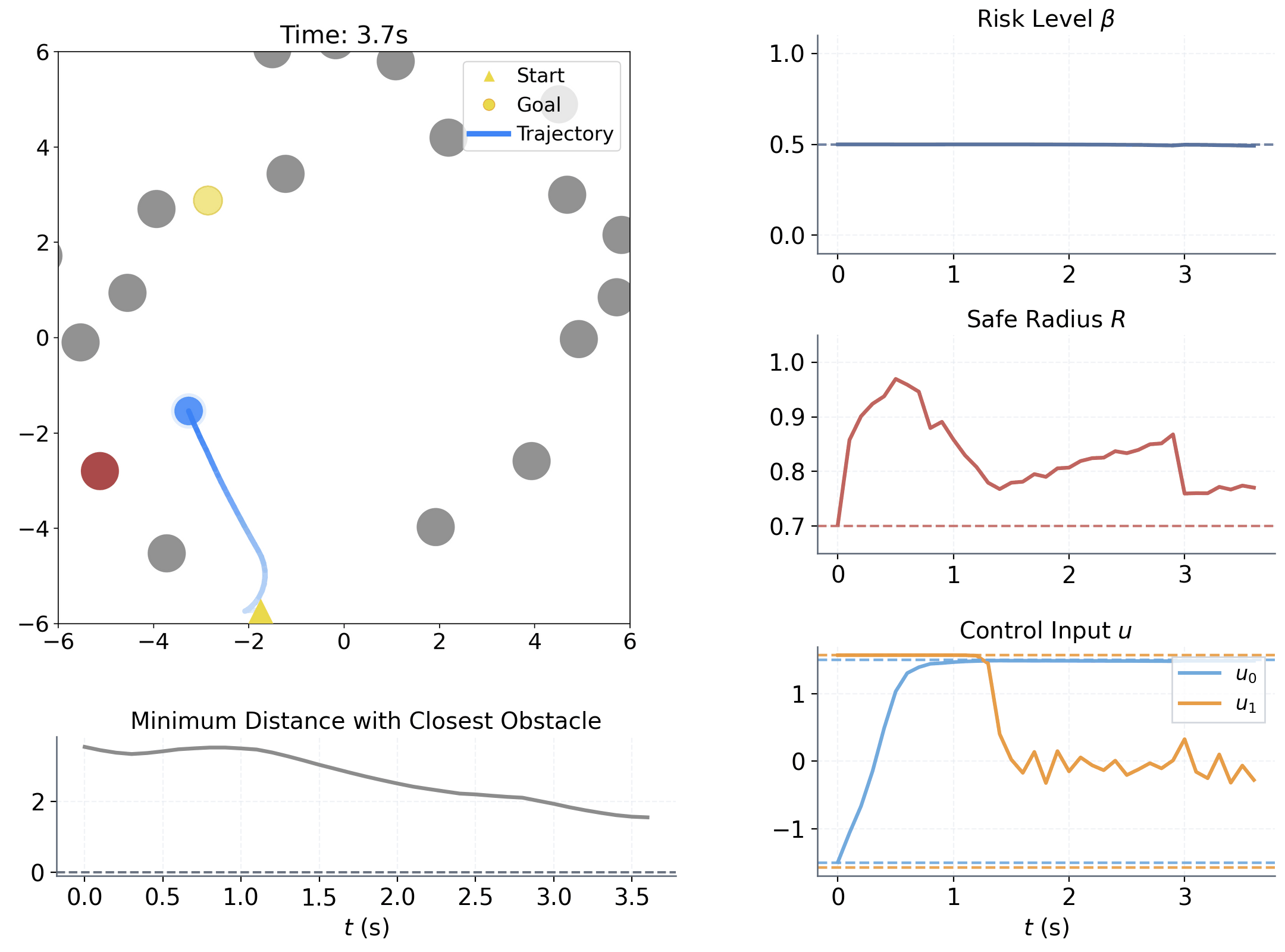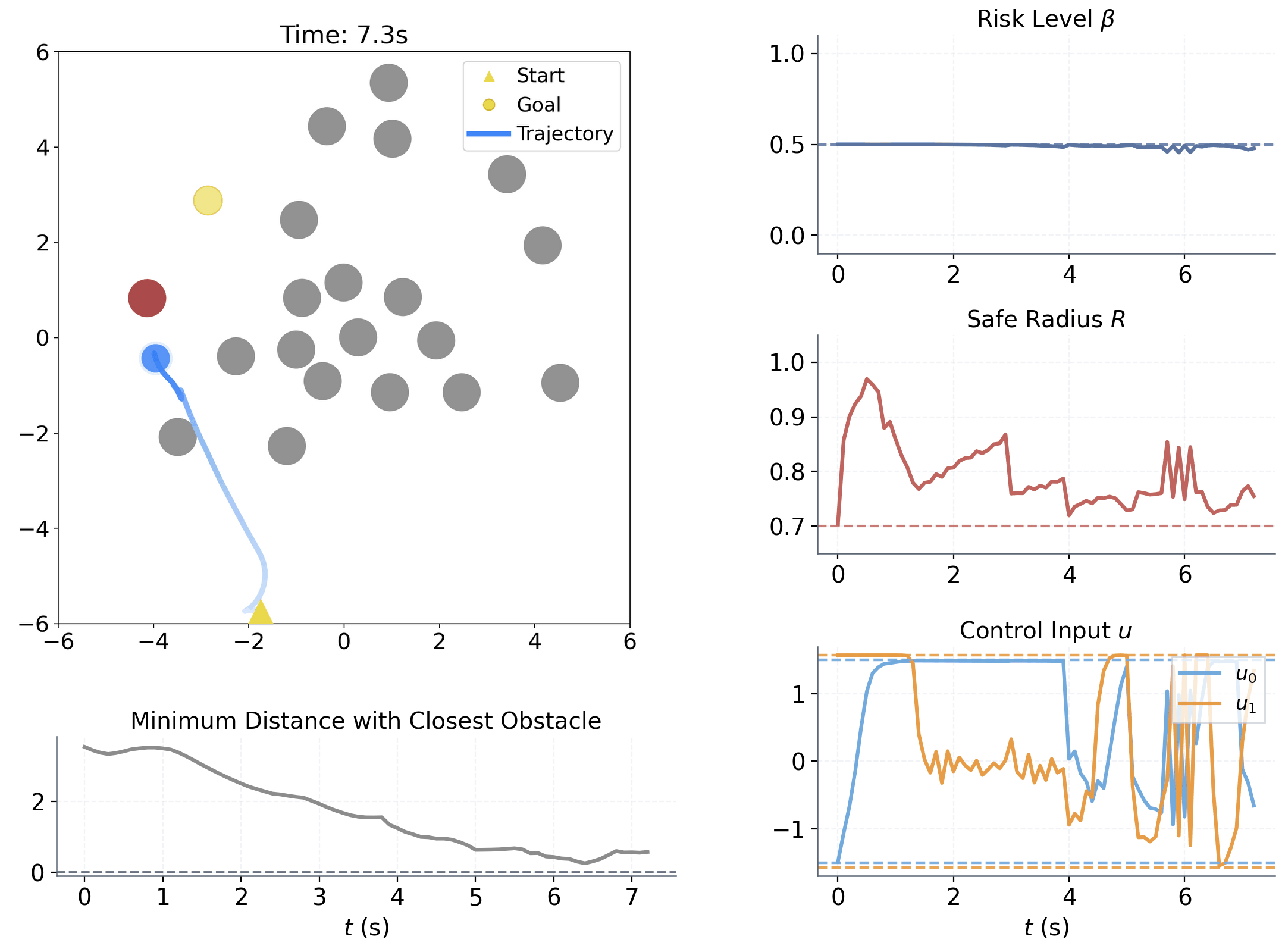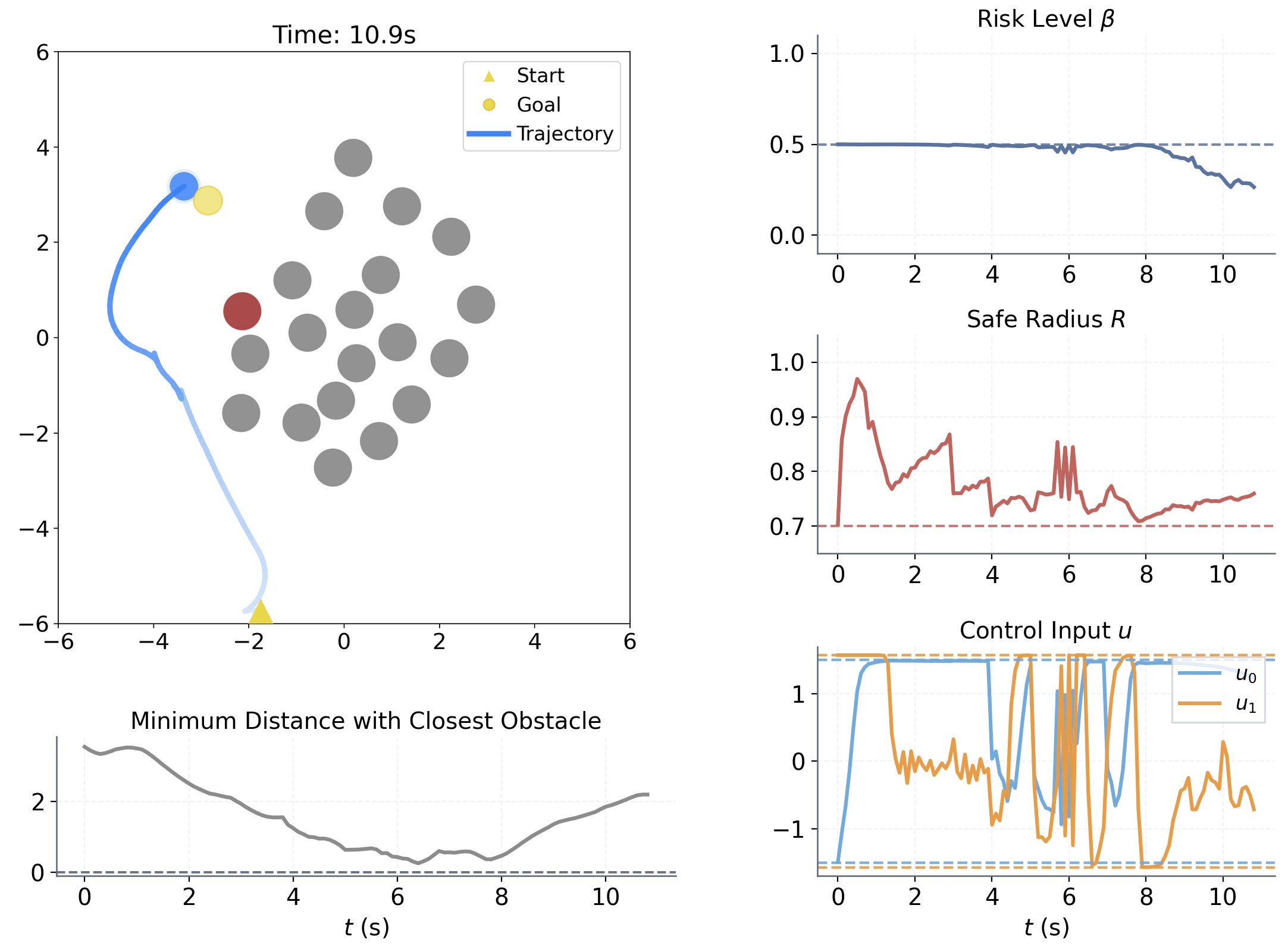
Method Overview
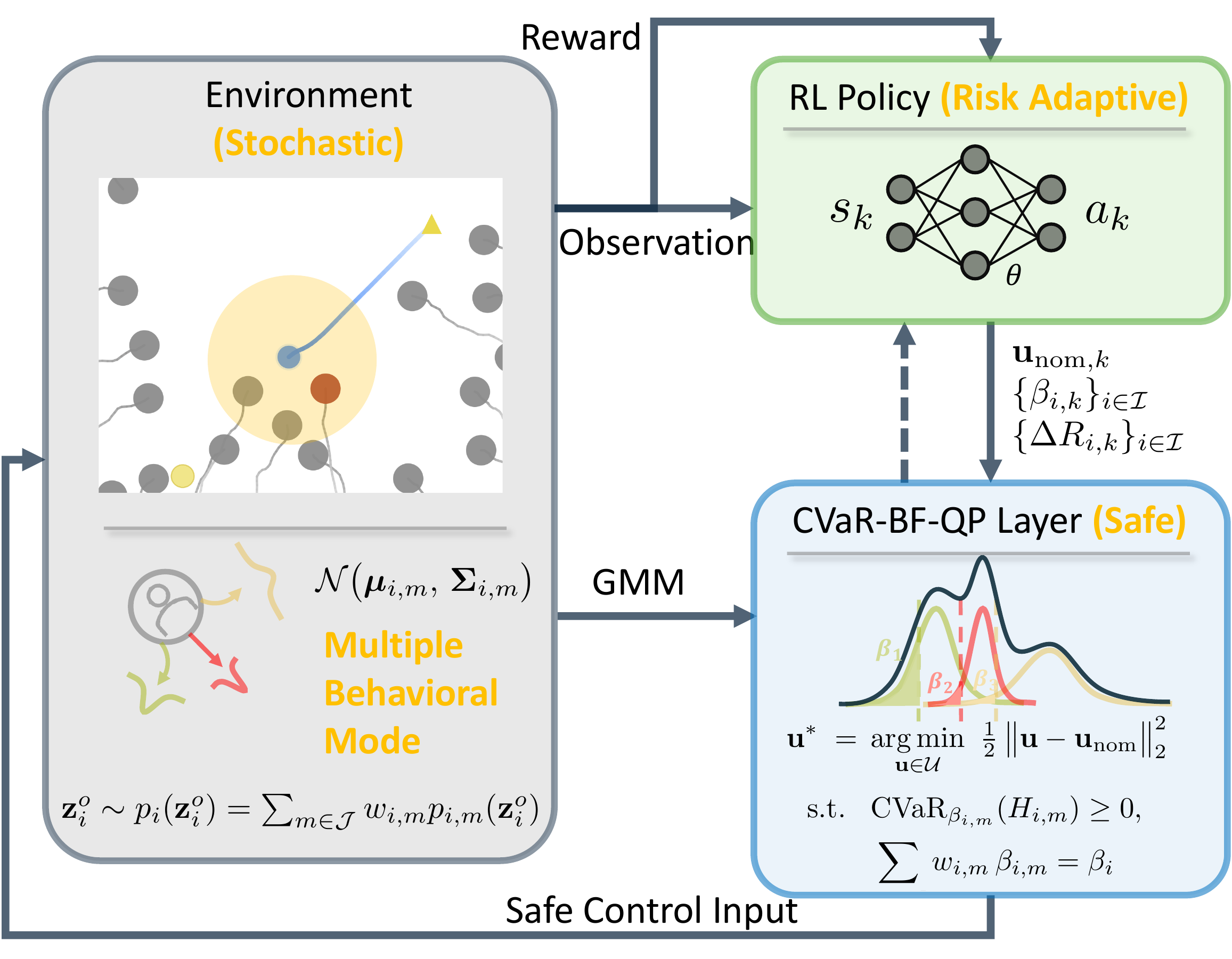
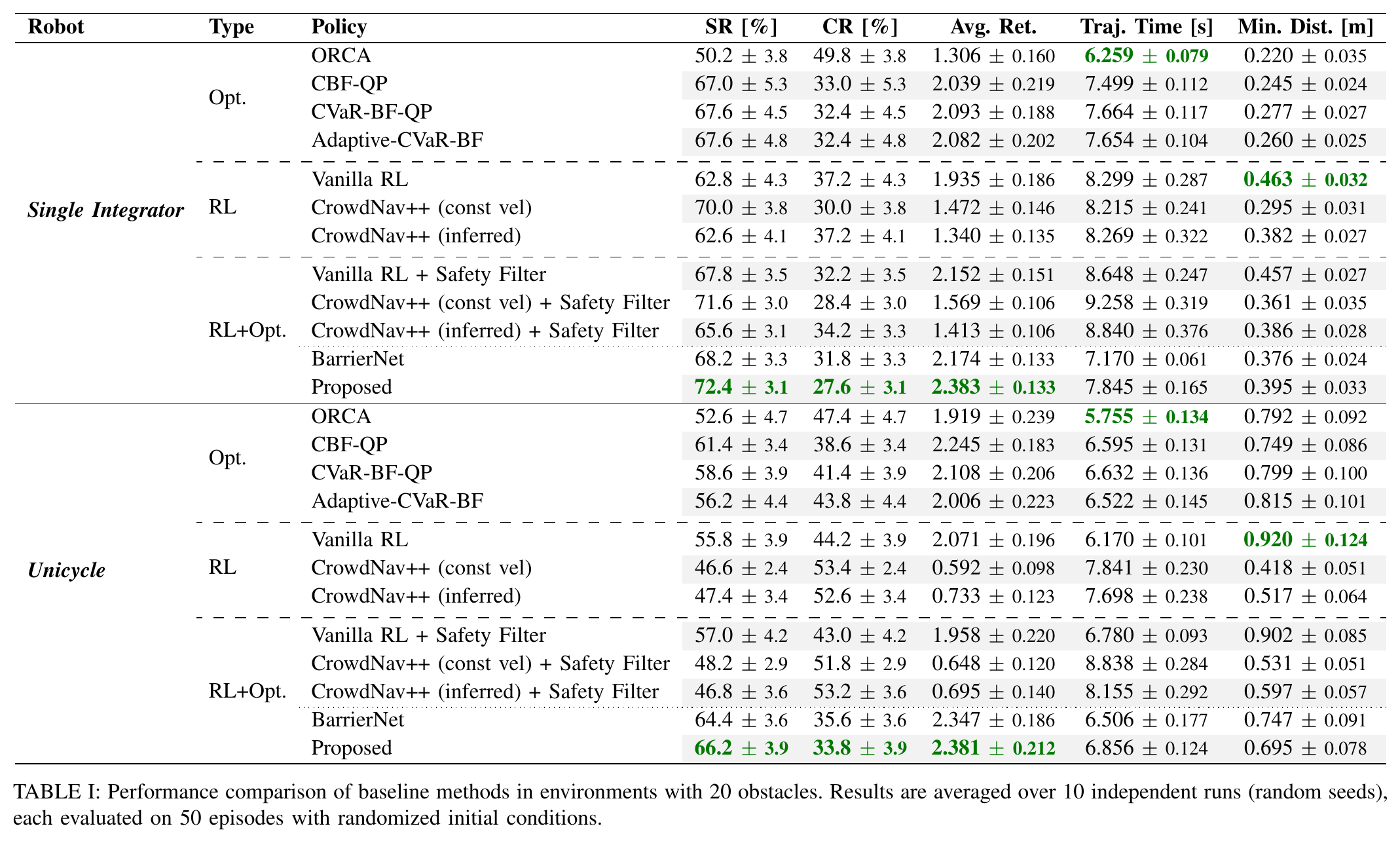
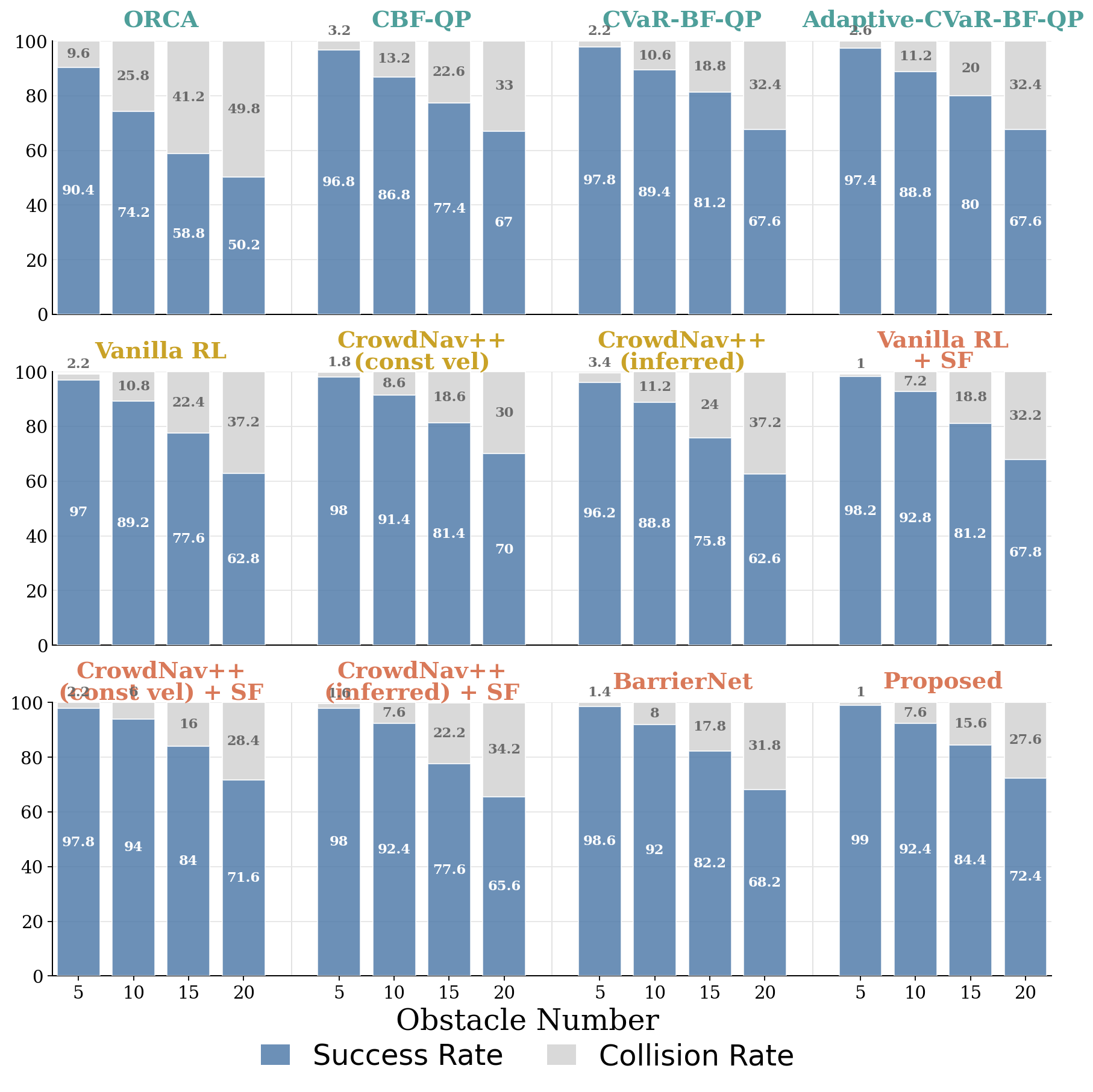
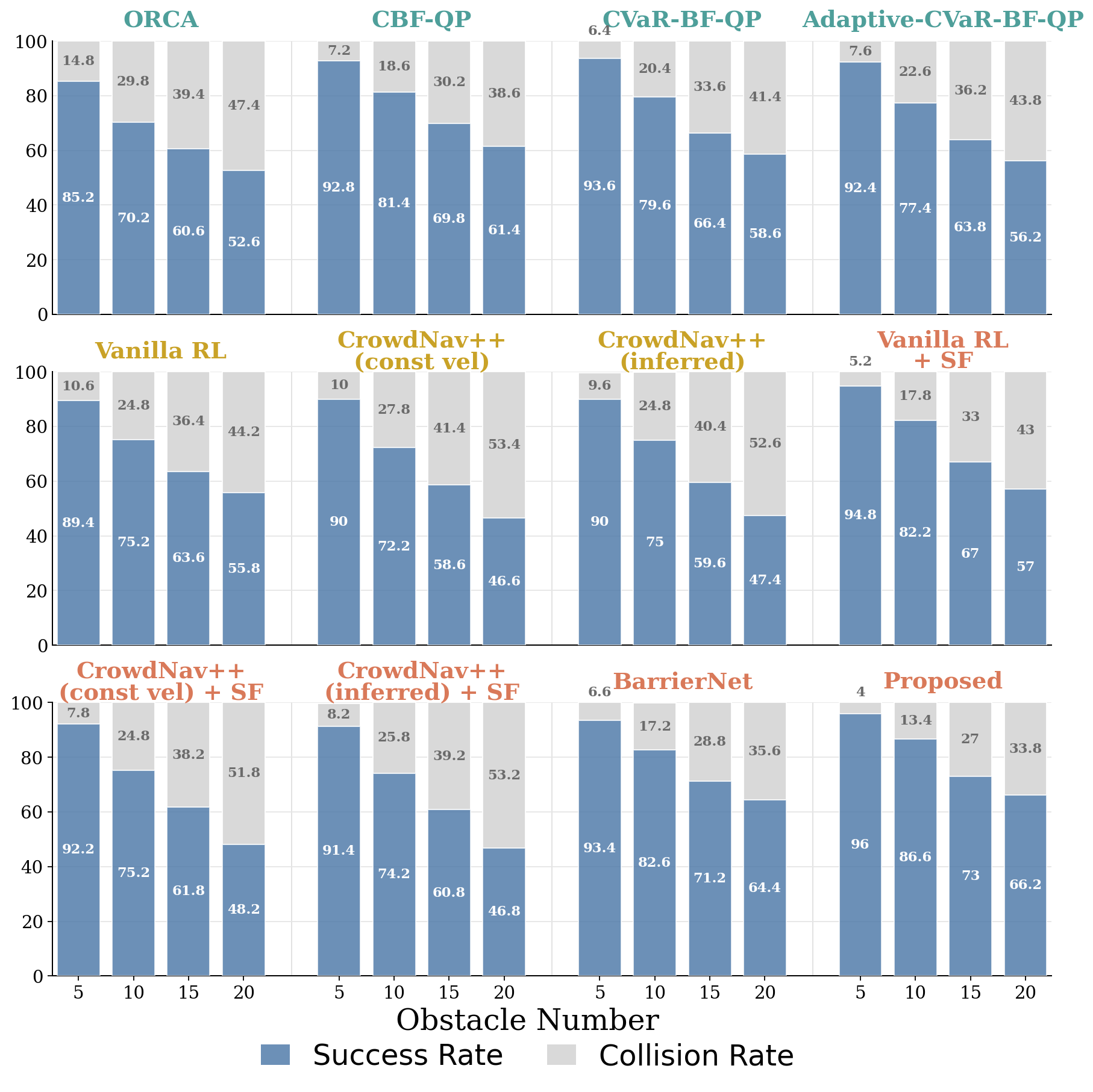
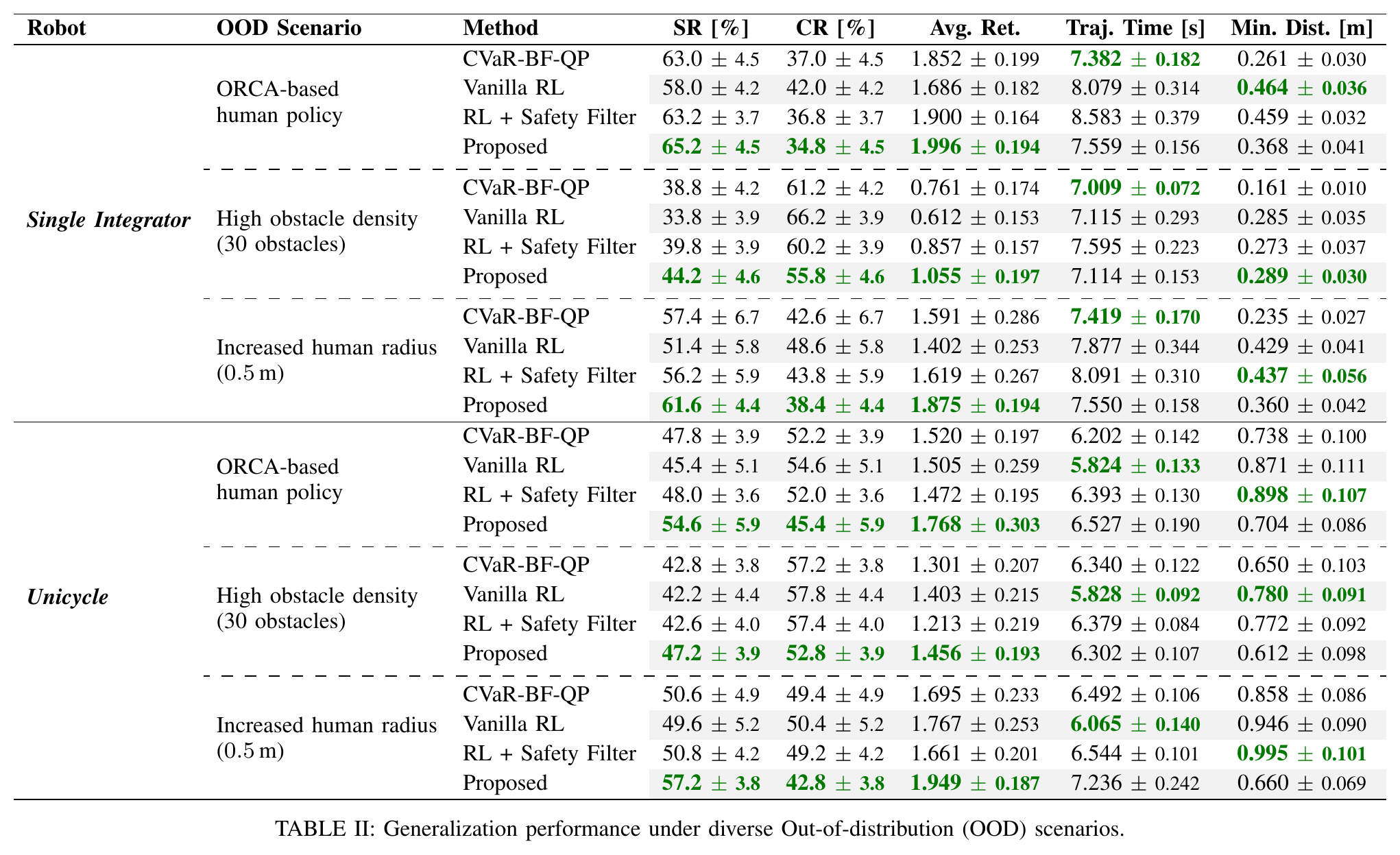
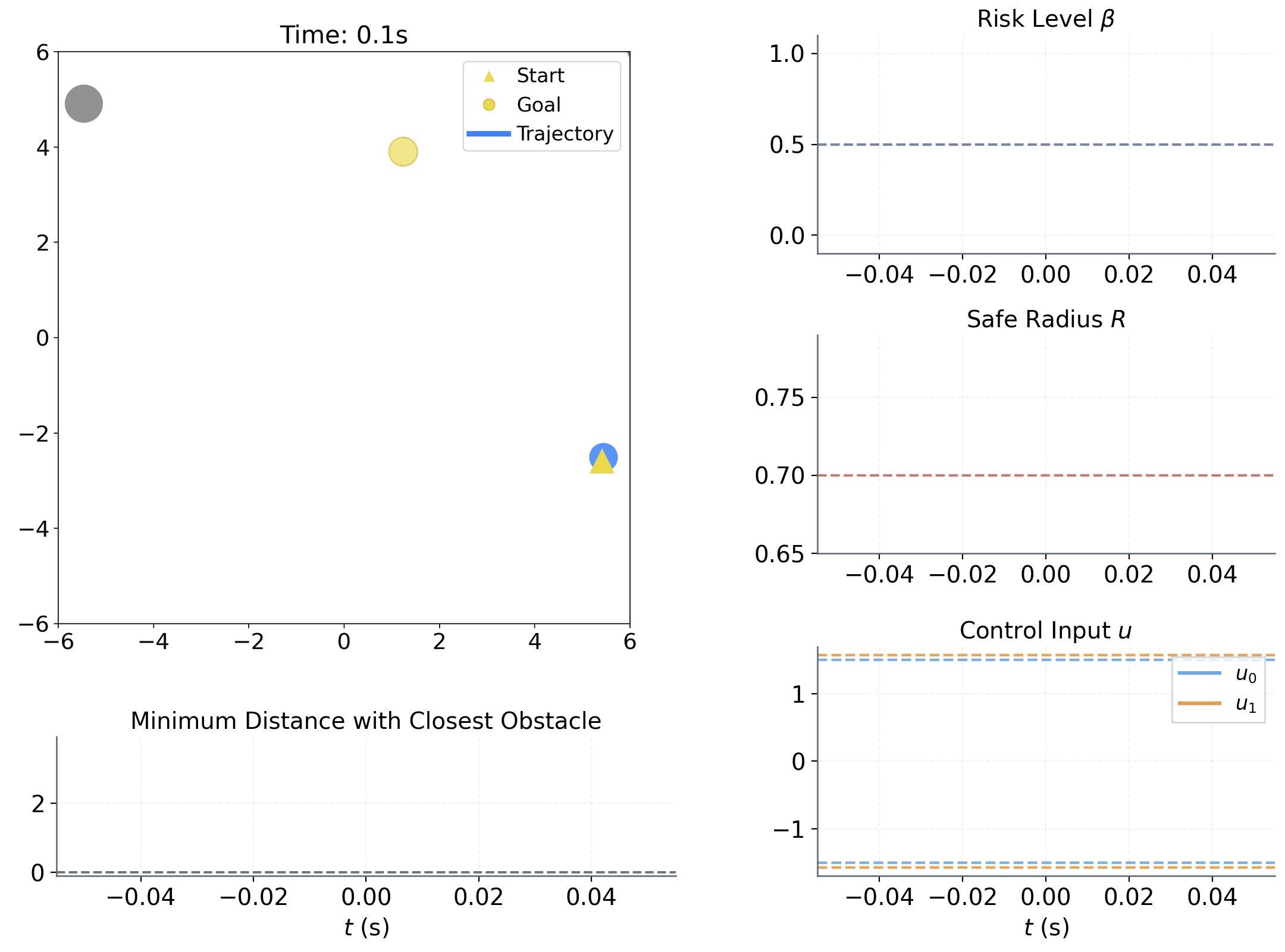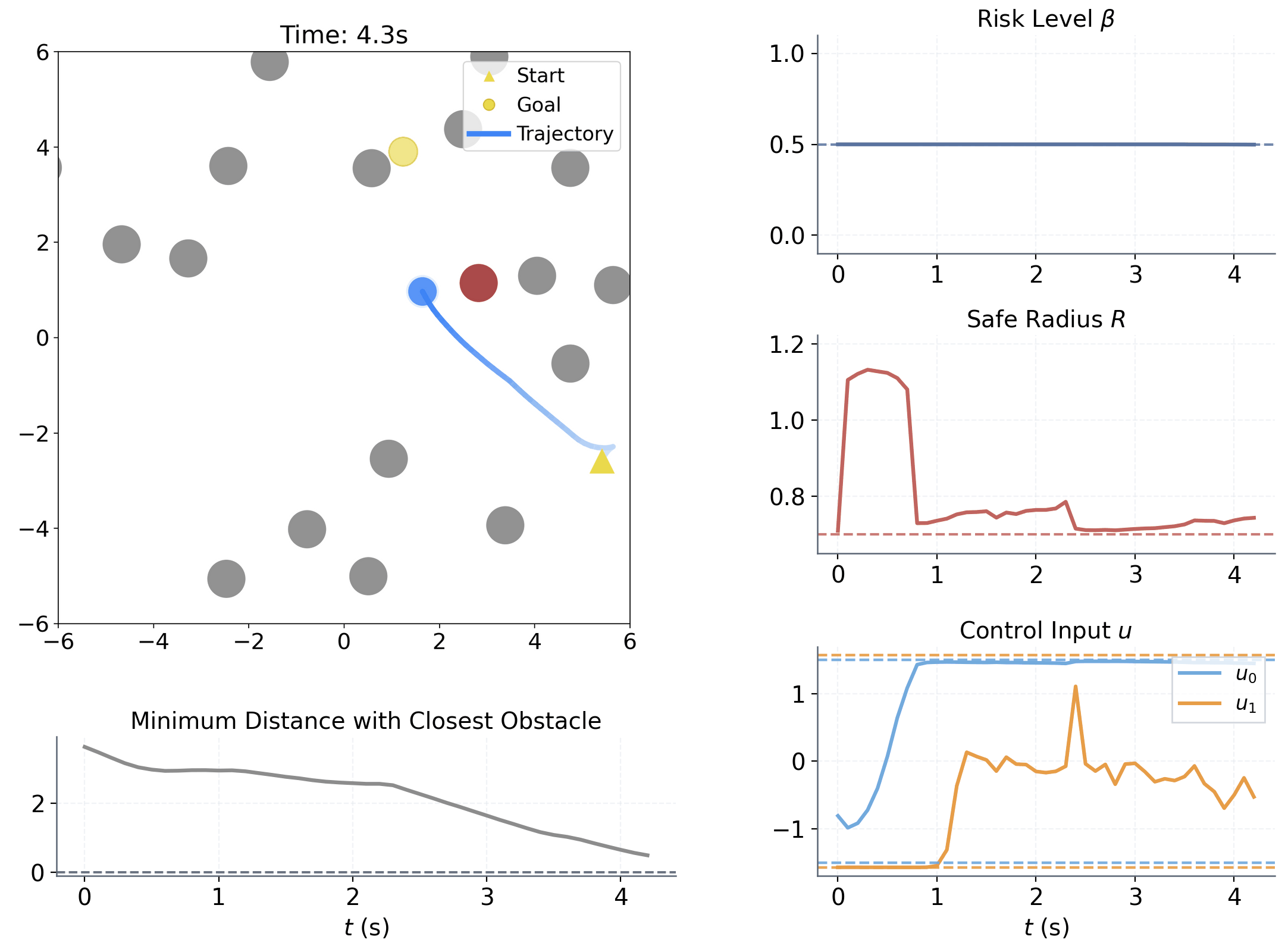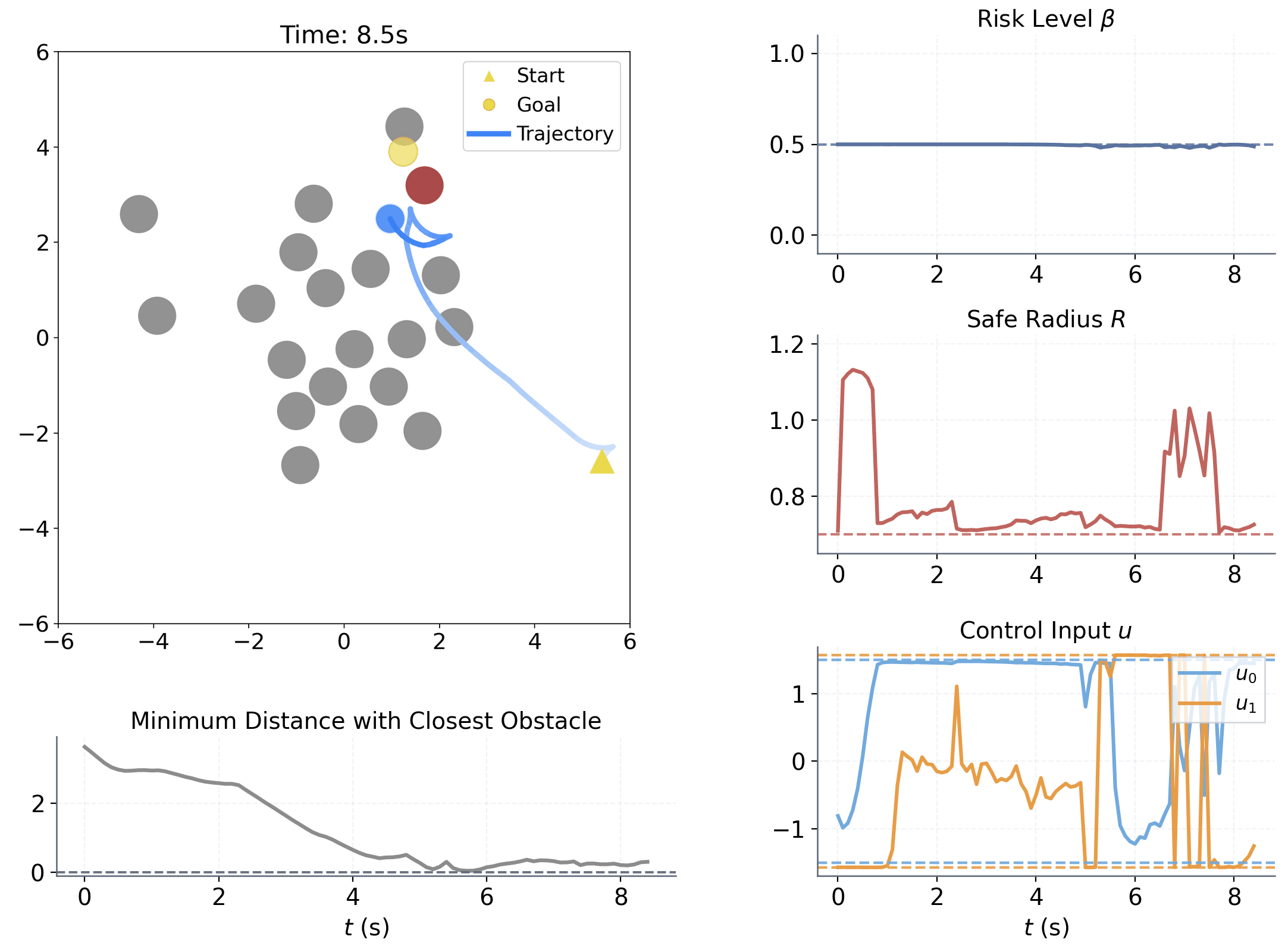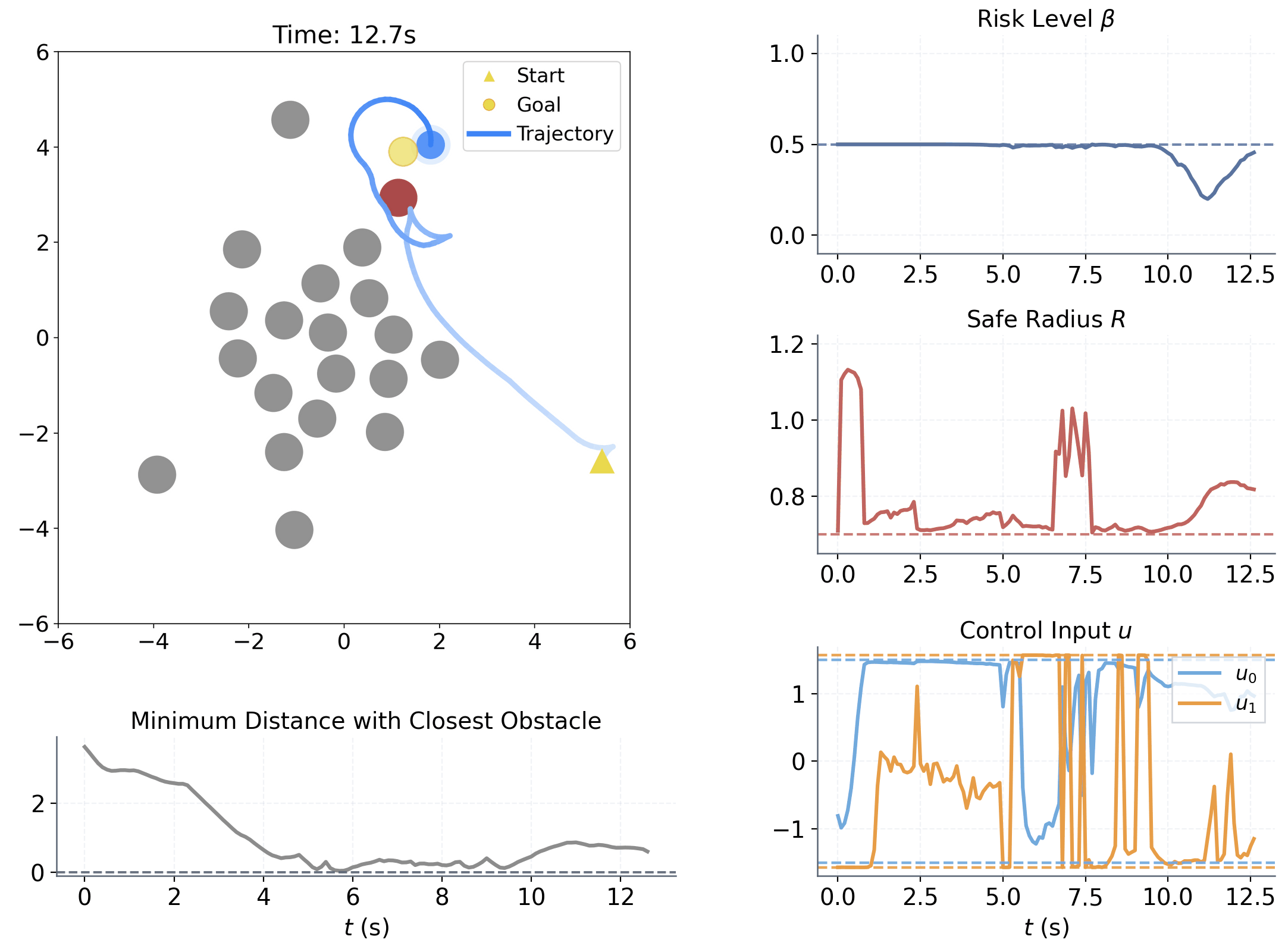
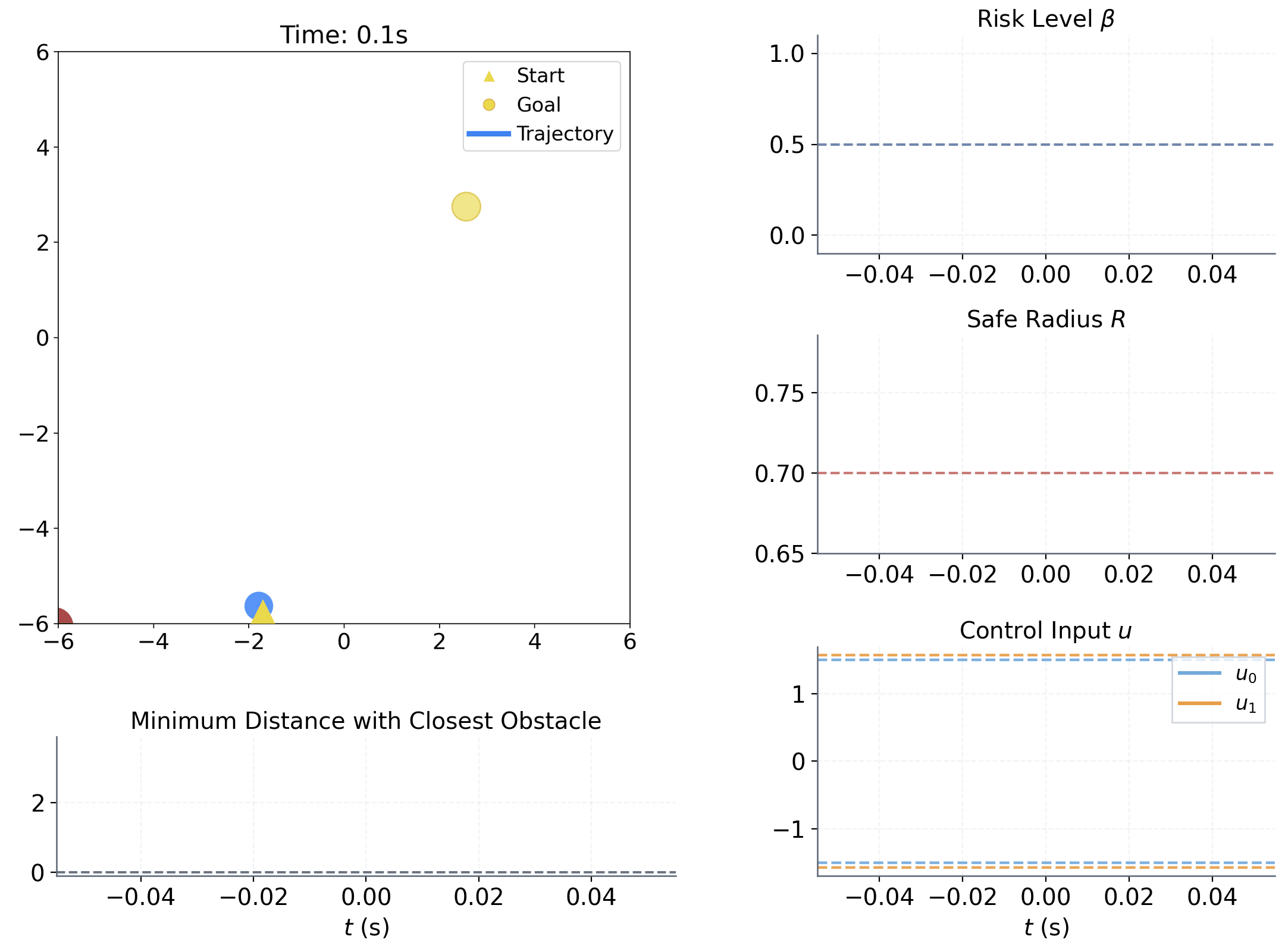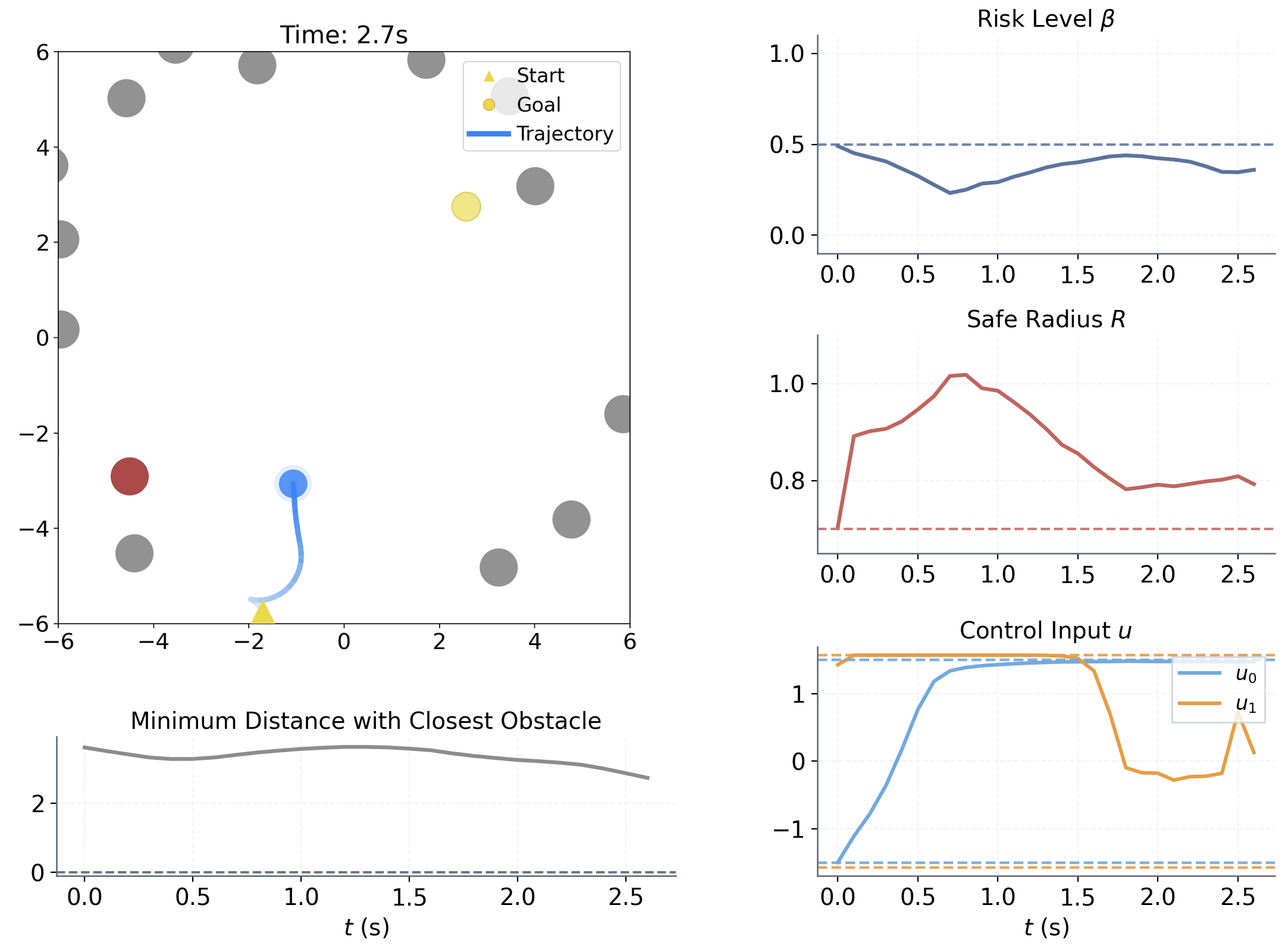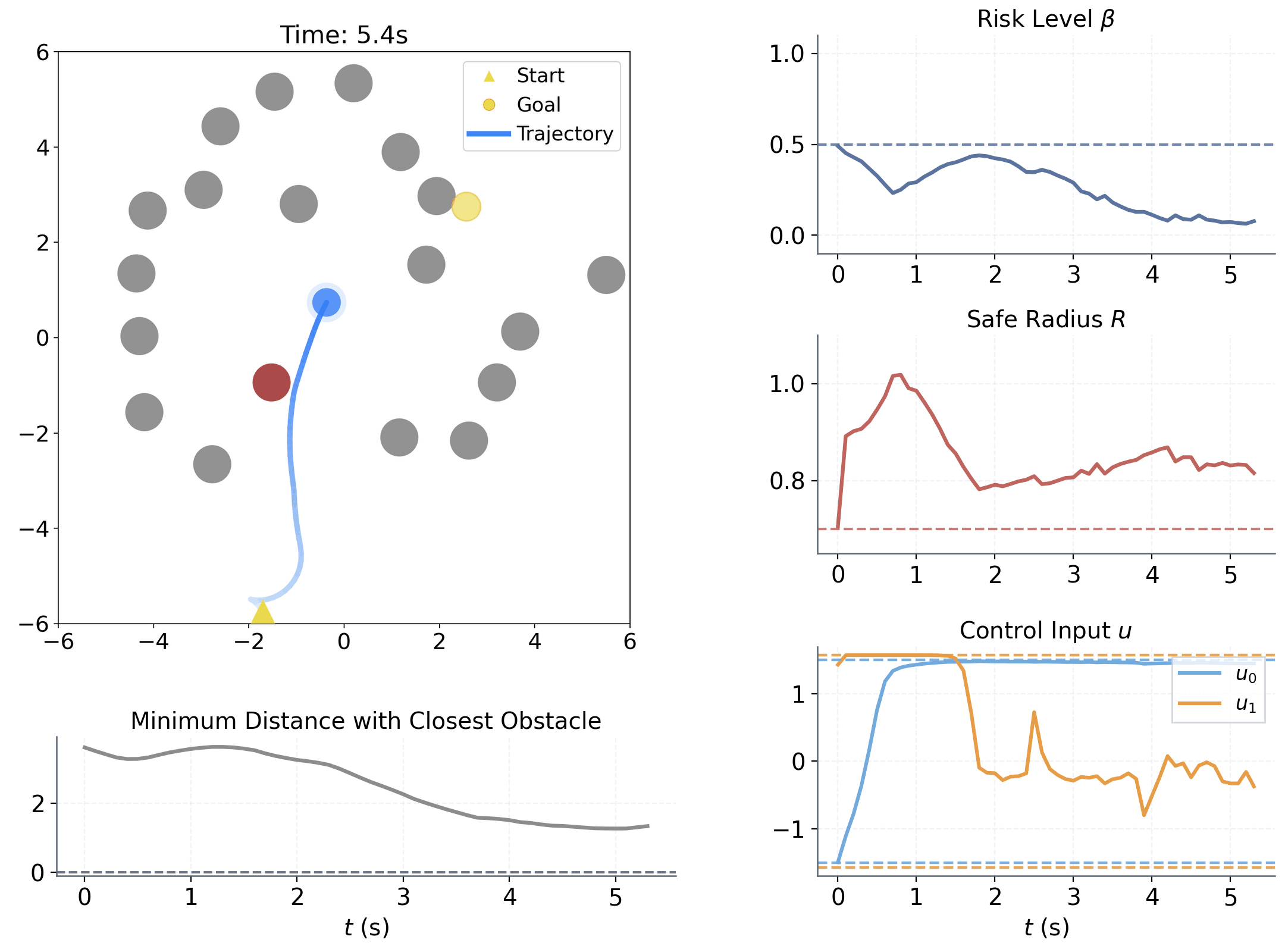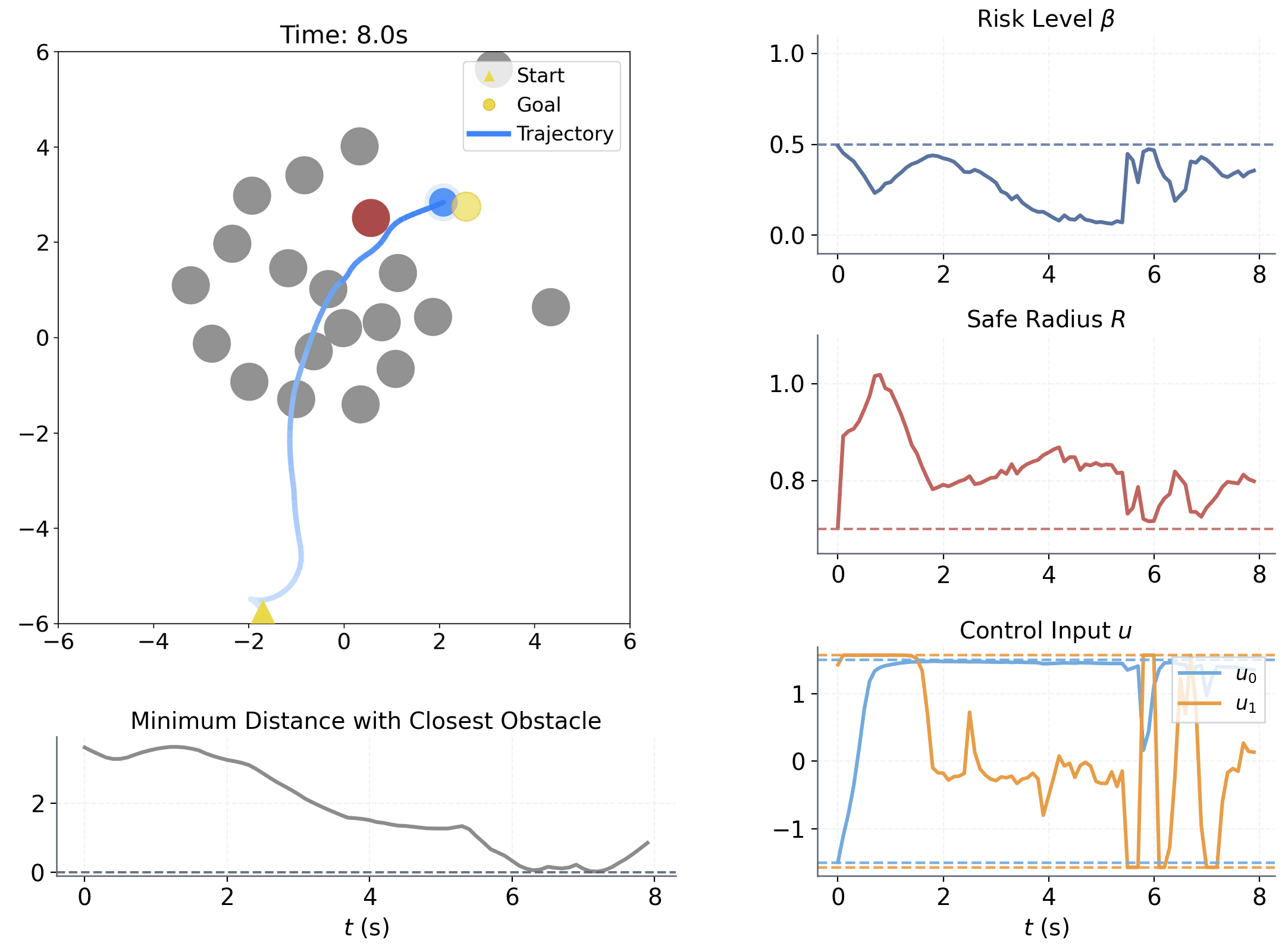
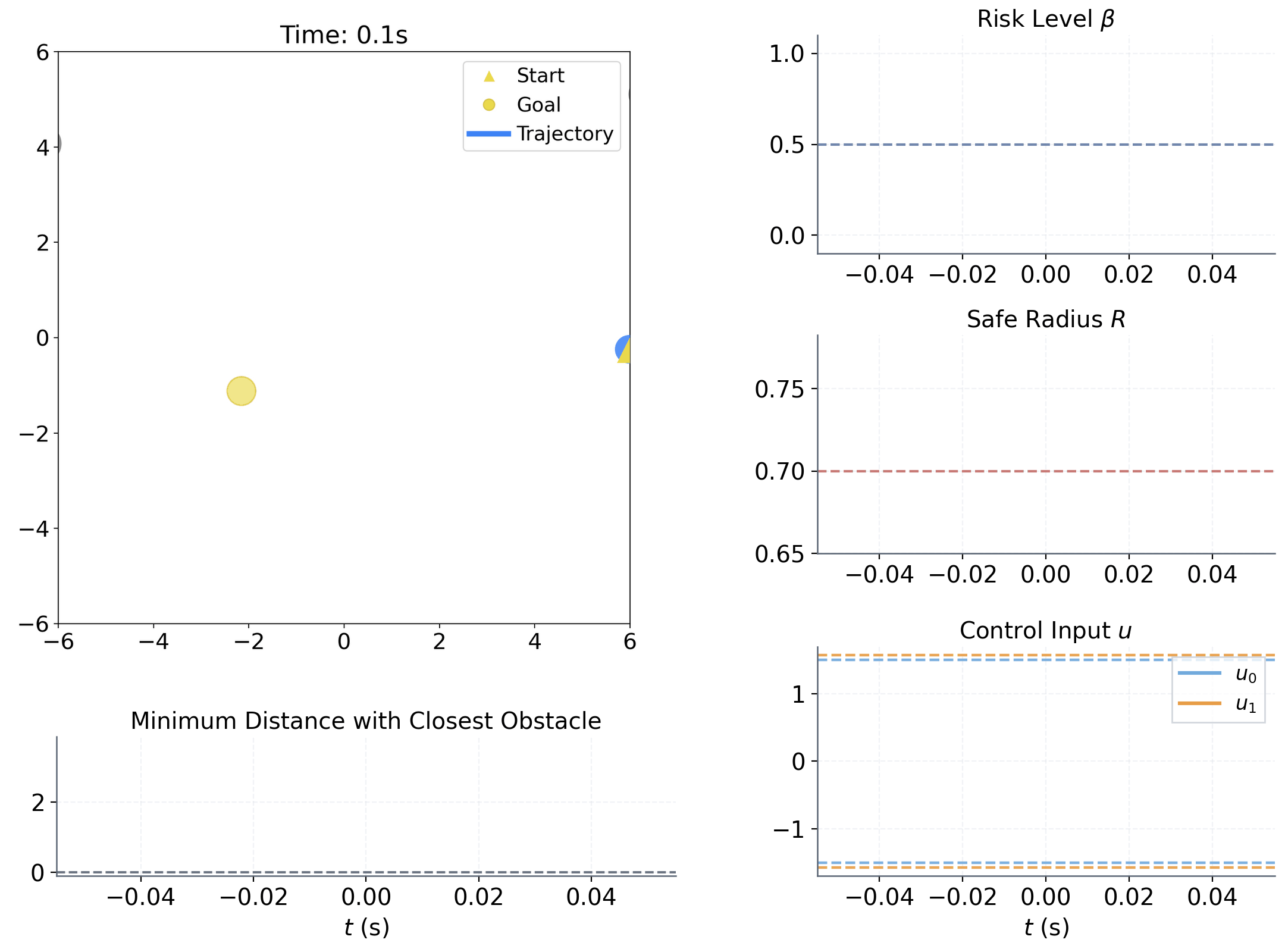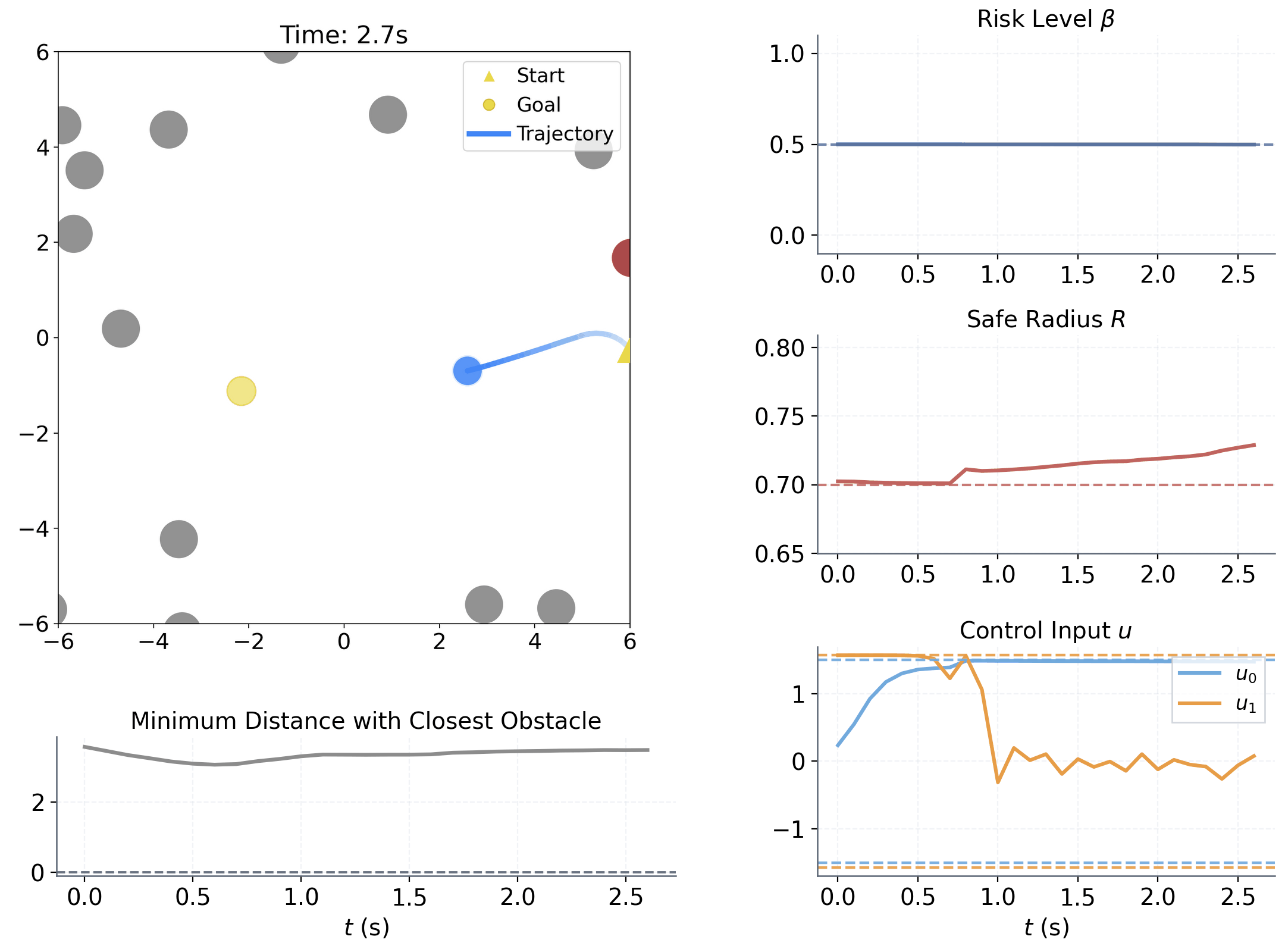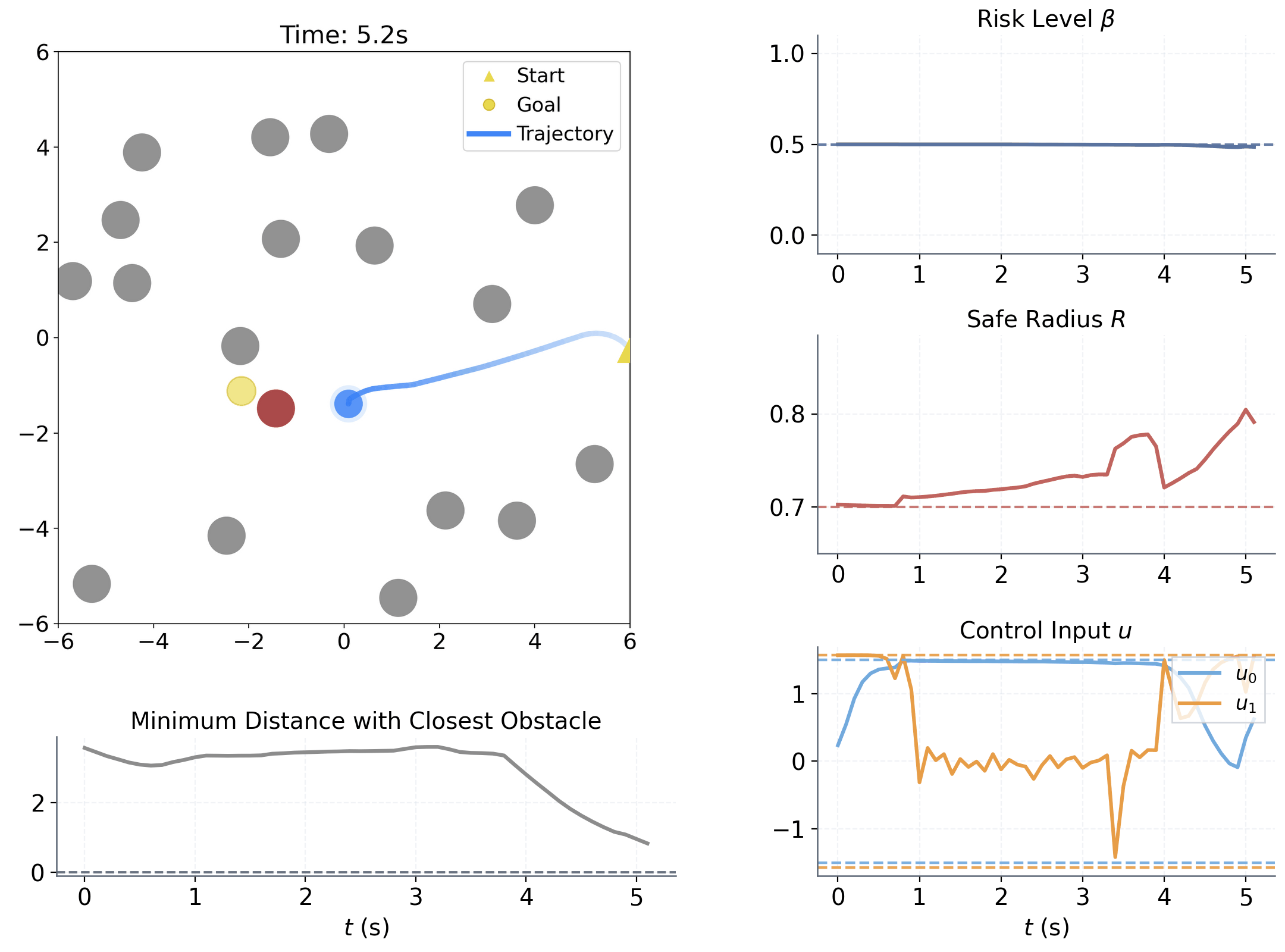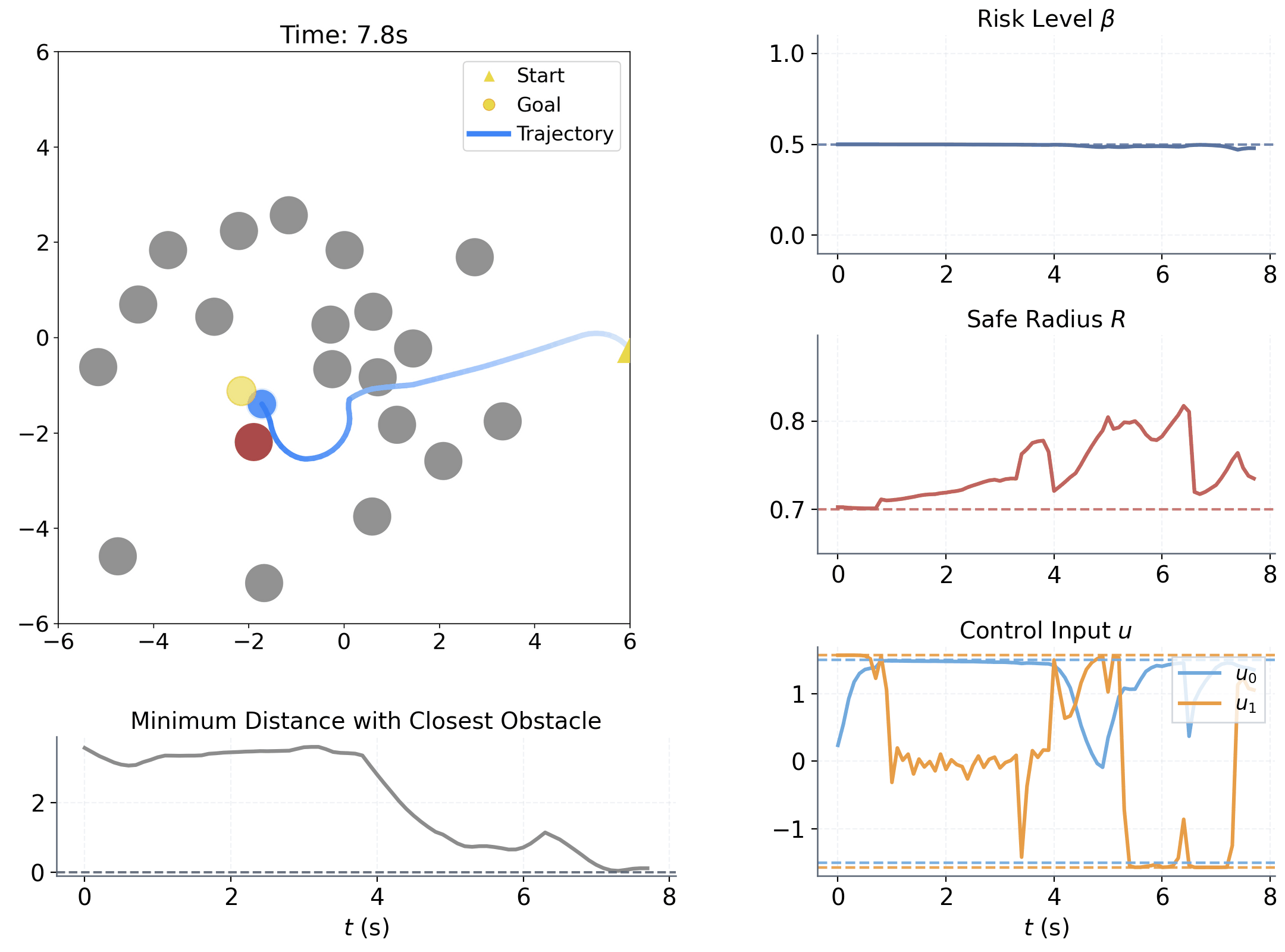
Learning to adapt risk online is critical for navigation in uncertain crowds. We present an end-to-end risk-adaptive framework that combines reinforcement learning with a differentiable CVaR barrier-function safety layer, jointly learning nominal control, risk level, and safety margin while enforcing probabilistic safety guarantees. This lets the robot stay cautious in difficult interactions without becoming unnecessarily conservative, and it performs strongly across varying obstacle densities, robot models, and OOD crowd shifts.
The coupling between risk level β and safety margin ΔR improves behavior in two key ways:
Drives maximum efficiency.
Adjusts sensitivity to high-risk interactions within [0, βu]
Adjusts adaptive spatial buffer when extra caution is needed.
min 1/2 ||u - unom||2 subject to CVaRβ(Hm(ΔR)) >= 0,
Provides a probabilistic safety guarantee.
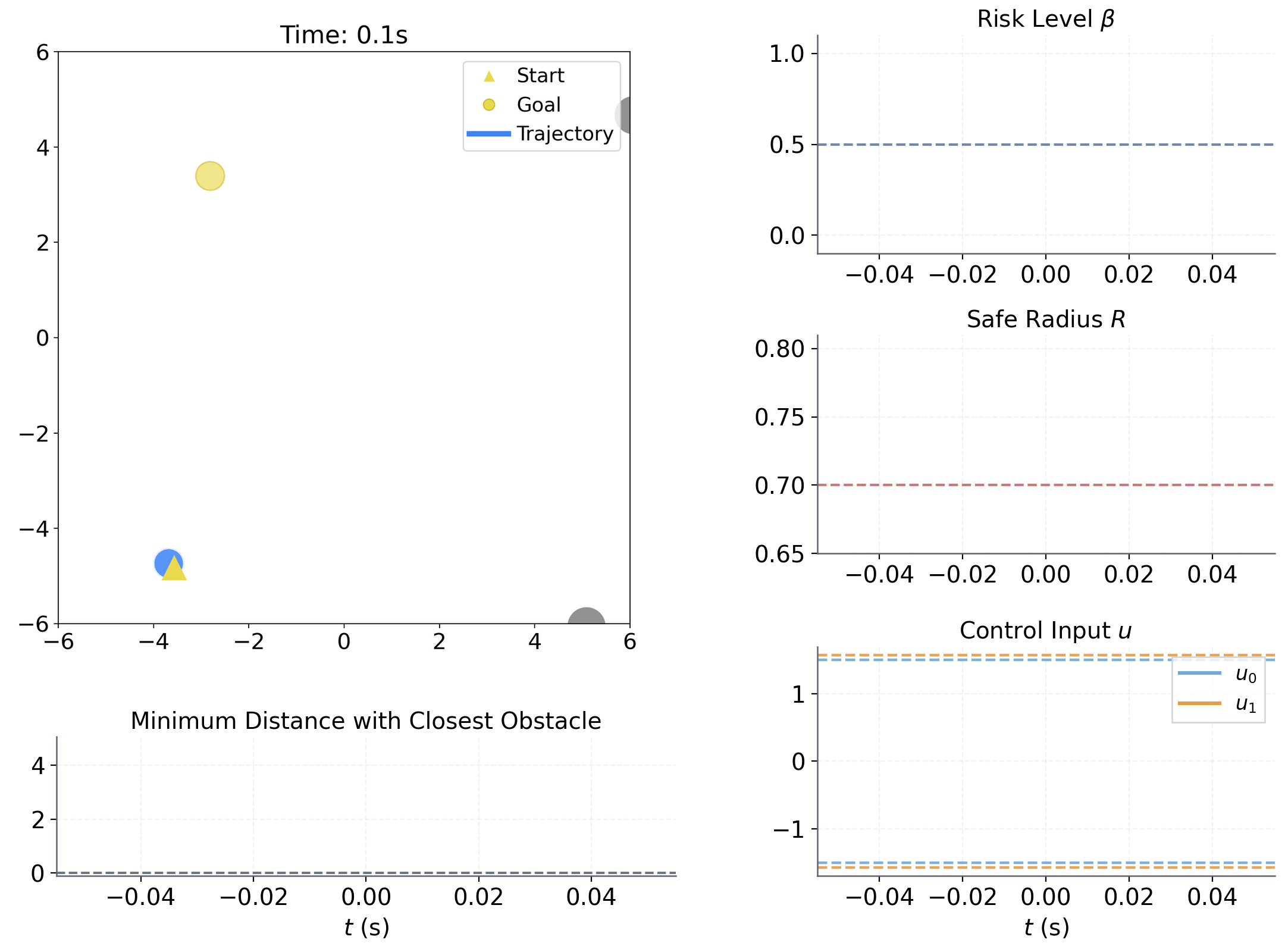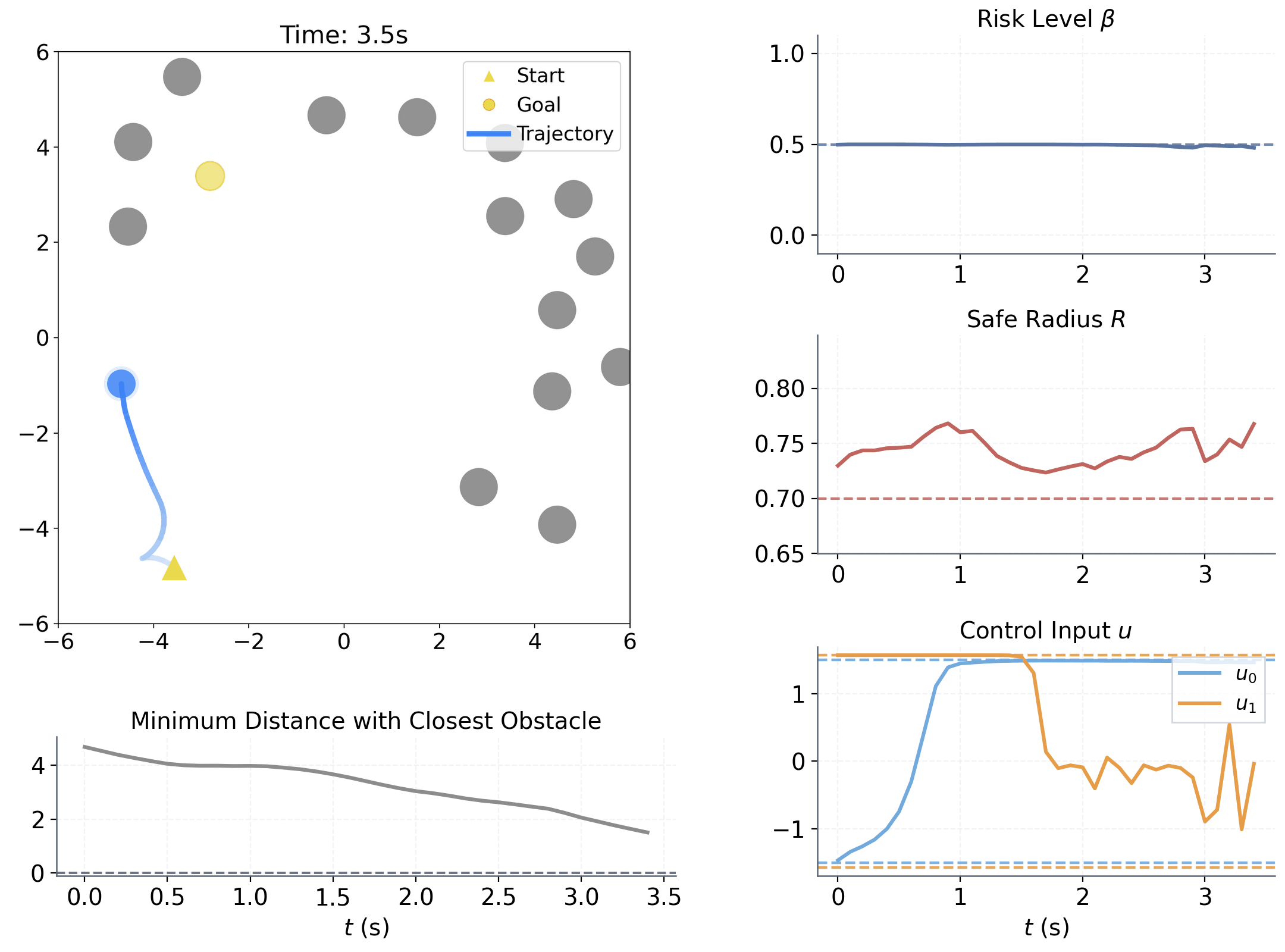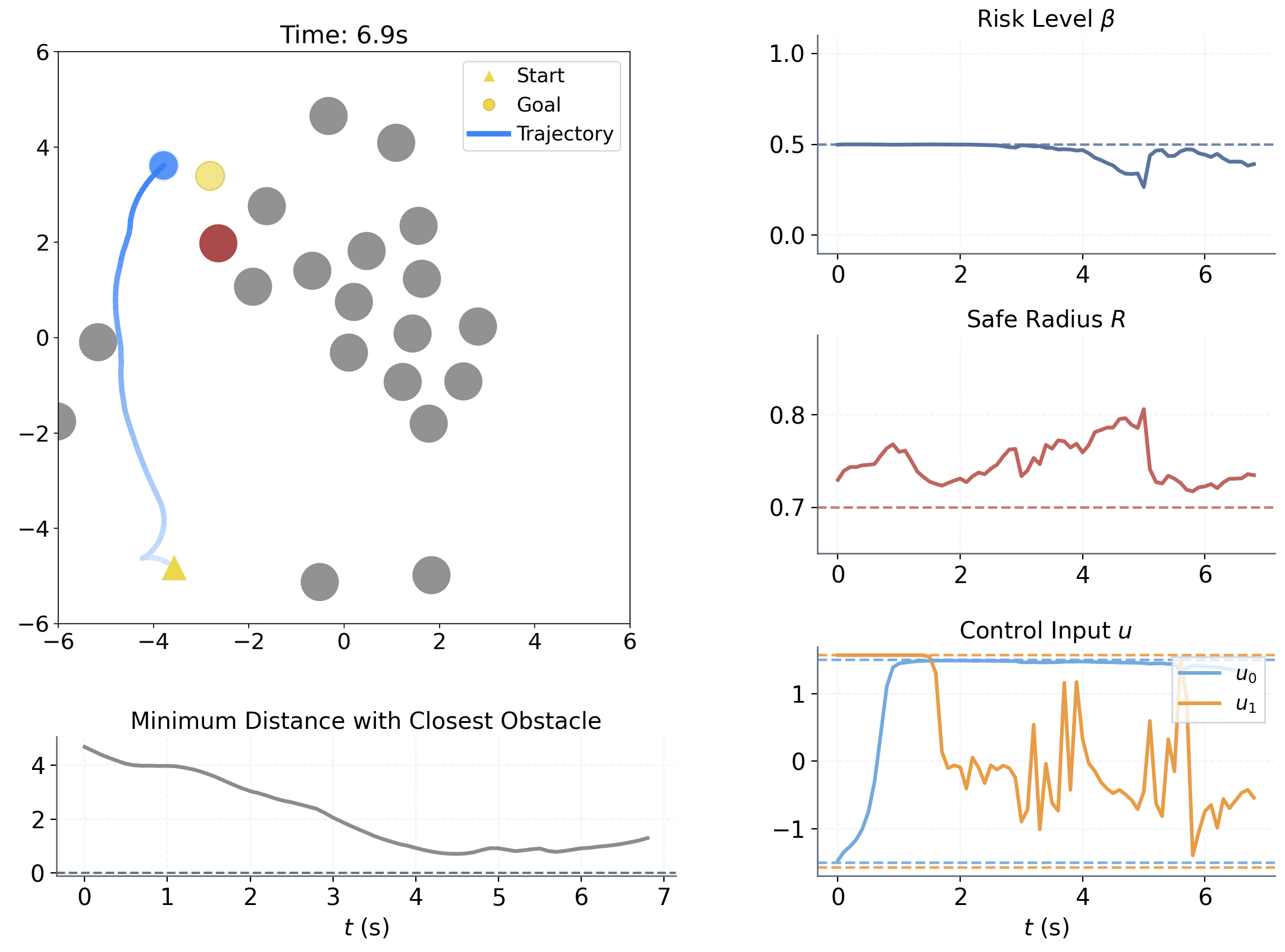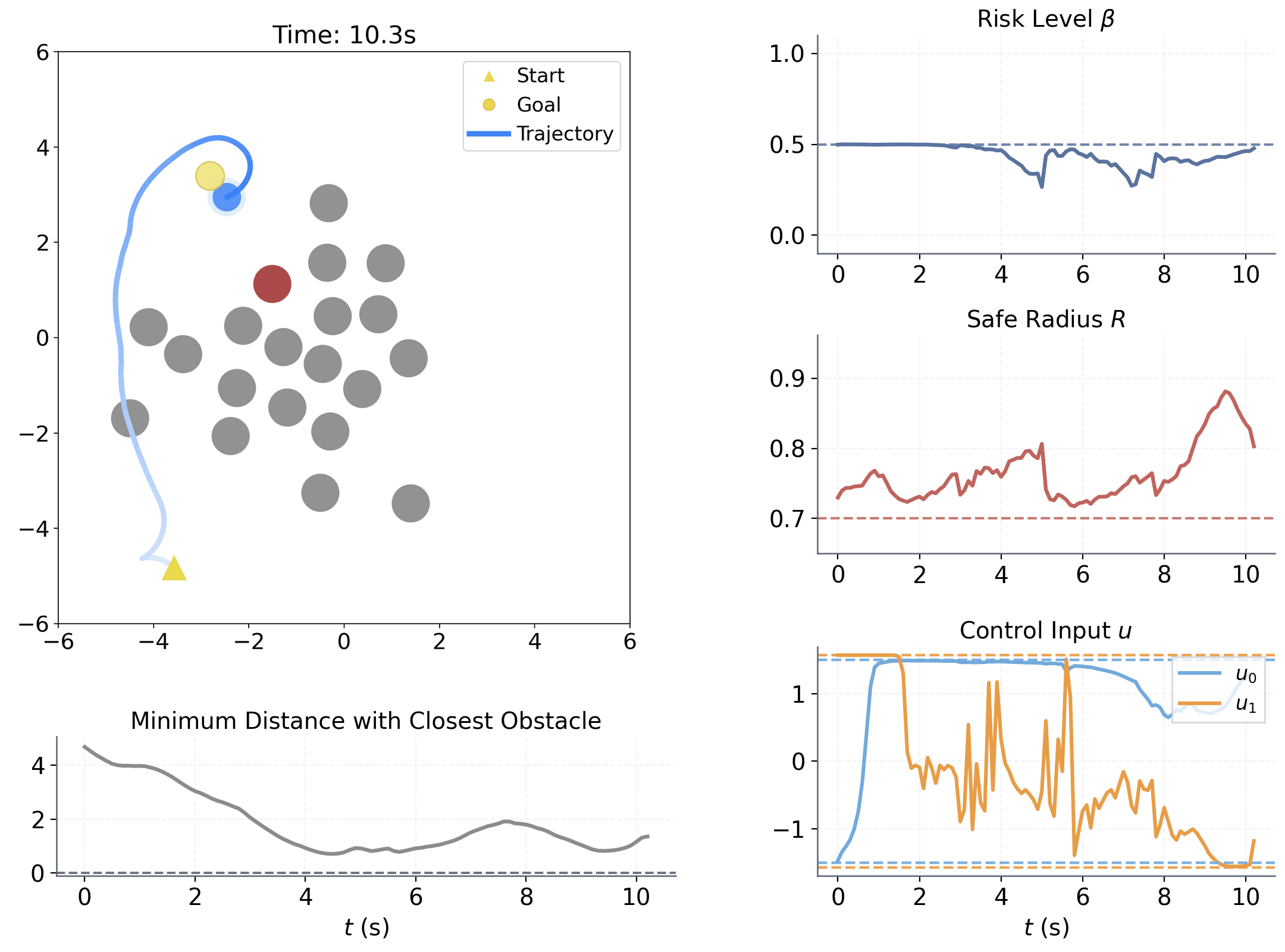
| Aspect | Setting | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Obstacle Uncertainty Models |
|
||||||||
| Control Limits |
|
||||||||
| Policy Action |
|
||||||||
| Baselines |
|